

Hace unos meses que el proyecto phoenix ha salido de la incubadora de apache. Por
esta razón he decidido hacer unas pruebas de concepto para ver como se
podría integrar los cubos R-OLAP basados en mondrian y
consumidos desde la interfaz de saiku como componente de
servidor de pentaho. ¿por qué puede ser interesante esto?.
- Mondrian es un proyecto que traduce queries MDX a SQL
- Phoenix es un proyecto que traduce queries SQL a queries de HBase
Por tanto integrando phoenix en pentaho podríamos consumir los datos
almacenados en un tablón tipo Hbase.
Siguiendo este artículo
y configurando superando algunos temas menores es bastante
sencillo crear cubos OLAP desde pentaho que realmenta utilicen como
backend datos almacenados en HBase. Los temas que hay que tener en
cuenta son
- Los jars a añadir al directorio lib del bi-server
- La configuración del datasource desde pentaho (generic database)
- El detalle de los nombres de las tablas en mayusculas al crear las
tablas desde la linea de comandos provista por phoenix
A continuación muestro unas capturas de las pruebas realizadas
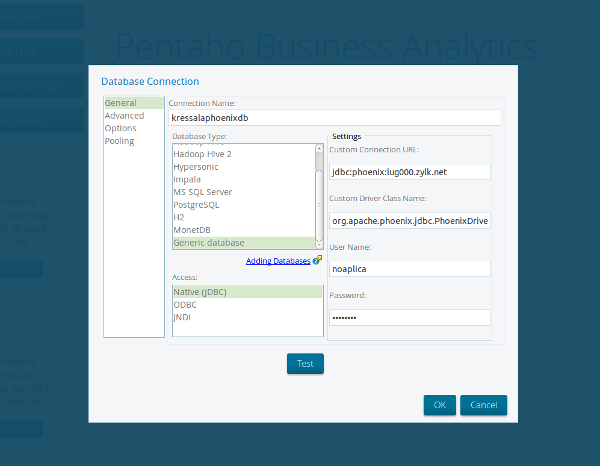
y como se vería el cubo
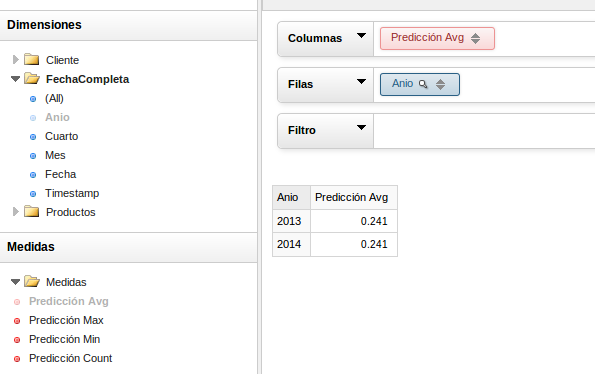
En realidad en este caso, dado
que mi laboratioro de hadoop/hbase es un pequeño juguete el
sistema es un poco lento y el tiempo de respuesta del cubo es un poco
superior al de mysql. En este caso lo único que quería probar era el
funcionamiento de phoneix y ver que tipo de coprocesadores y de
problemas podía tener su uso.
Por otro lado, también he probado a enganchar la herramienta kettle
(ETL) usando phoenix y el sistema de reporting…la verdad es que
todos ellos funciona de manera transparente usando el driver JDBC de
phoenix. Ahora solo queda hacer unas pruebas más orientadas a
rendimiento para ver si realmente es una solución que nos permita
escalar a cientos de millones los registros explotados por los cubos
OLAP …





