

Aplicando KMeans en el análisis de datos
Siguiendo estos dos artículos de internet, uno
donde se explica como crear un modelo aplicando el algoritmo no
supervisado de clusterización (KMeans) y el otro,
donde se explica usar Apache Spark desde el notebook zeppelin, he
creado un ejemplo que mezcla ambos. Para poder ejecutarlo en el
laboratorio de de bigdata que tenemos montado.
Lo que se ha hecho ha sido lo siguiente
- Cargar los datos de los bancos
- Seleccionar dos de sus características (edad, balance) y usarlas
como features para el algoritmo KMeans - Definir el número de agupaciones que quería para el cluster, 8 en
este caso - Definir que % de los datos se iban a usar para entrenar el modelo
y que % para hacer las predicciones - Aplicar el modelo
- Observar los resultados
El códio scala que he usado para ello es el siguiente, que se puede
pegar directamente en notebook de zeppelin
Primero los imports necesarios
import org.apache.spark._ import org.apache.spark.sql.SQLContext import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql._ import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.ml.clustering.KMeans val sqlContext = new SQLContext(sc) import sqlContext.implicits._ import sqlContext._
Después la definición de mapeo de los campos del csv que contiene los datos
val schema = StructType(Array(
StructField("age", IntegerType, true),
StructField("job", StringType, true),
StructField("marital", StringType, true),
StructField("education", StringType, true),
StructField("default", StringType, true),
StructField("balance", DoubleType, true),
StructField("housing", StringType, true),
StructField("loan", StringType, true),
StructField("contact", StringType, true),
StructField("day", IntegerType, true),
StructField("month", StringType, true),
StructField("duration", IntegerType, true),
StructField("campaign", IntegerType, true),
StructField("pdays", IntegerType, true),
StructField("previous", StringType, true),
StructField("poutcome", StringType, true),
StructField("y", StringType, true)
))
Una vez hecho esto, importamos el fichero csv y cargamos el csv como
un dataFrame para su posterior uso. En este punto hemos tenido
que añadir la dependencia de com.databricks.spark.csv como un
artifact al interprete de spark de zeppelin. En caso de no
hacerlo esta parte dará un error. También hemos dejado el fichero de
bank-full.csv en el HDF en la carpeta /tmp del hdfs. Este fichero se
puede descargar del tutorial indicado en la introducción.
val df = sqlContext.read.format("com.databricks.spark.csv")
.option("header", "true")
.option("delimiter",";")
.schema(schema).load("/tmp/bank-full.csv")
Una vez creado el dataFrame las "features" que van a ser
usadas para tipificar los puntos y que KMeans pueda decidir
que puntos tienen similtud con qué puntos y permita así las
clasificación de los mismos. Para KMeans las features
tienen que ser numéricas (ya que opera con el concepto de distancia,
la agrupación la hace en base a la proximidad de los puntos), por
tanto si quisieramos usar el género como parte de nuestra
clasificación o el estado civil, habría que hacer una transformación
de este dato para poder usarlo.
val featureCols = Array("age","balance")
val assembler = new VectorAssembler().setInputCols(featureCols).setOutputCol("features")
val df2 = assembler.transform(df)
Indicamos que % de los datos se van a usar para entrenar y que % se
va a usar par hacer el test en este caso 70/30
val Array(trainingData, testData) = df2.randomSplit(Array(0.7,0.3))
Una vez preparados los datos aplicaremos el modelo, en este
caso con K de 8, es decir que nos agrupe los datos en 8 agrupaciones.
val kmeans = new KMeans().setK(8).setFeaturesCol("features").setPredictionCol("prediction")
val model = kmeans.fit(df2)
val categories = model.transform(testData)
Y ya podríamos hacer queries al modelo creado
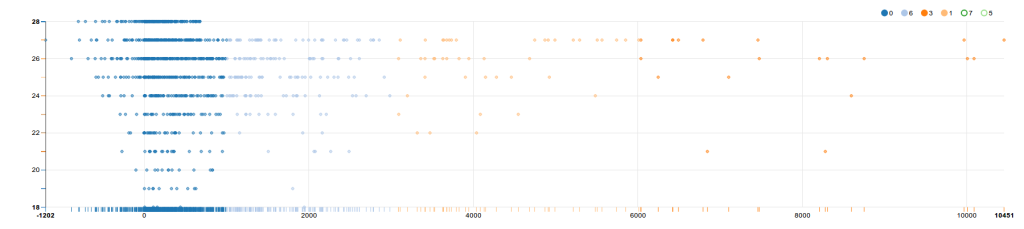
z.show(categories.groupBy("prediction").count())

O una query un poco más compleja que nos permite ver que
rangos de edad incluye cada grupo del cluster
z.show(categories.select($"age",$"balance",$"prediction").groupBy("age","balance","prediction").agg(count("prediction")).orderBy("age","balance","prediction"))

El ejemplo, desde el punto de vista de negocio no significa
nada, es un mero ejercicio técnico que nos ha permitodo
explorar la comprobar que se pùeden usar las técnicas de machine
learning con un conjunto de datos de prueba, usando nuestro
laboratorio. Es muy recomendable leer con atención los dos post
indicados al comienzo, ya que explican con un grado de detalle mucho
mayor que este post el uso de ML en spark.
Además a diferencia de este post, el post relacionado con el
caso de uso de uber si que tiene valor de negocio.





