

Uno de los procesos más usuales en la implantación o migración
de un gestor documental es la carga de contenidos. Esta carga (inicial
o no) puede requerir desplegar una estructura de espacios y documentos
en Alfresco, y en casos avanzados de una migración de sus permisos (de
owner y heredados), metadatos y versiones. Una herramienta que viene
de serie con Alfresco es el módulo de
importación de Filesystem Bulk, que permite migrar datos desde
unidades locales en el servidor, estructuras de directorios y
documentos a través de unos servicios REST expuestos por el módulo.
Los tiempos de carga son realmente mejores que mediante cualquier otro
método basado en CIFS, Webdav o via API (como CMIS o WS) o incluso
ACPs (Alfresco Content Package).
de un gestor documental es la carga de contenidos. Esta carga (inicial
o no) puede requerir desplegar una estructura de espacios y documentos
en Alfresco, y en casos avanzados de una migración de sus permisos (de
owner y heredados), metadatos y versiones. Una herramienta que viene
de serie con Alfresco es el módulo de
importación de Filesystem Bulk, que permite migrar datos desde
unidades locales en el servidor, estructuras de directorios y
documentos a través de unos servicios REST expuestos por el módulo.
Los tiempos de carga son realmente mejores que mediante cualquier otro
método basado en CIFS, Webdav o via API (como CMIS o WS) o incluso
ACPs (Alfresco Content Package).
La importación se realizar a través de un webscript en la url:
http(s)://alfrescoserver/alfresco/service/bulkfsimport
donde se especifican principalmente:
-
El directorio de contenidos a importar (Import
directory): Directorio local del servidor a importar. -
El espacio objetivo (Target space): Espacio de
Alfresco o nodo de Alfresco donde se va a importar la estructura
local especificacda. Dispone de una búsqueda live query de espacios
sobre el repositorio.
Dispone de opciones para:
- Deshabilitar las reglas de contenido.
- Reemplazar los archivos, que indica si está permitido modificar
documentos en caso de que ya existan en la carpeta destino. - El tamaño del batch en una transacción (tipicamente el número de
cores *2 = p.ej 4) - El número de hilos paralelos a ejecutar durante el proceso (por
ejemplo 100). Si hay un error fallará todo el batch.
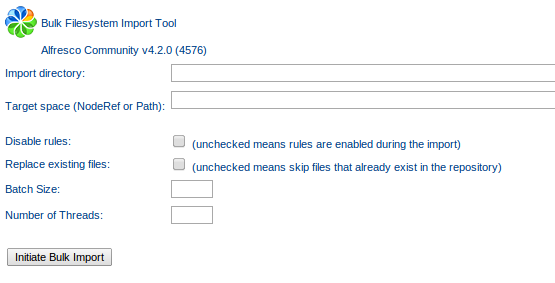
Se puede ejecutar via el formulario o incluso via
curl. Hay ciertas restricciones como comenta la documentación
del módulo.
- No hay soporte de AVM.
- Sólo un import puede hacerse cada vez (debido al JobLockService).
- El acceso a la herramienta de importación está restringida a los
administradores de Alfresco y no a los usuarios potenciales del ECM.
Os dejo algunas recomendaciones a la hora de hacer una importación:
– Parametrizar el alfresco-global.properties para
que no haga esfuerzos durante las cargas.
que no haga esfuerzos durante las cargas.
# ECM content usages/quotas system.usages.enabled=false system.enableTimestampPropagation=false
– Parametrizar los batches de carga (también se especifican en el formulario).
# Numero de threads: numero de cores * 2 bulkImport.batch.numThreads=4 # Tamaño del batch bulkImport.batch.batchSize=100
– Configurar el logger de la carga en el custom-log4j.properties
en el directorio extension para obtener más información sobre la
carga realizada y los errores:
en el directorio extension para obtener más información sobre la
carga realizada y los errores:
log4j.logger.org.alfresco.repo.batch.BatchProcessor=info log4j.logger.org.alfresco.repo.transaction.RetryingTransactionHelper=info
– Minimizar los postprocesos cuando sea posible, porque no van a
ser lo adecuado de cara al rendimiento. Por ejemplo, reglas de
contenido que realizan transformaciones de determinados espacios.
ser lo adecuado de cara al rendimiento. Por ejemplo, reglas de
contenido que realizan transformaciones de determinados espacios.
– Deshabilitar SOLR durante la carga: Cada 15 segundos el tracker
de SOLR está indexando los contenidos por defecto, y esto hace el
proceso más lento. Para ello es necesario editar los archivos
solrcore.properties y setear la variable
enable.alfresco.tracking a false. Tambien se puede
hacer via JMX o Alfresco Share Admin Console.
de SOLR está indexando los contenidos por defecto, y esto hace el
proceso más lento. Para ello es necesario editar los archivos
solrcore.properties y setear la variable
enable.alfresco.tracking a false. Tambien se puede
hacer via JMX o Alfresco Share Admin Console.
– No dejar que se actualice continuamente la página de status del
proceso. Aunque es interesante en la actualización continua del
proceso se puede perder algo de rendimiento.
proceso. Aunque es interesante en la actualización continua del
proceso se puede perder algo de rendimiento.
– Si los procesos de carga son continuos, puede ser adecuado montar
un servidor dedicado de carga que no interfiera con el servicio de los usuarios.
un servidor dedicado de carga que no interfiera con el servicio de los usuarios.
– Cuando el proceso de bulk acaba puede ser necesario comprobar los
nodos con un script como este (tambien
es posible obtener más información sobre esto aquí).
nodos con un script como este (tambien
es posible obtener más información sobre esto aquí).
– Puedes migrar metadatos a través ficheros XML adjuntos en la
estructura de documentos y carpetas. Incluso es posible trasladar
aquellos que tienen que ver con el aspecto
auditable de Alfresco (nombre, creador, fechas de modificación),
lo cual es muy interesante. Con los ACPs también es posible pero no
mediante métodos de carga basados en APIs CMIS, REST o WS.
estructura de documentos y carpetas. Incluso es posible trasladar
aquellos que tienen que ver con el aspecto
auditable de Alfresco (nombre, creador, fechas de modificación),
lo cual es muy interesante. Con los ACPs también es posible pero no
mediante métodos de carga basados en APIs CMIS, REST o WS.
– Para la versión Enterprise también existe un modo inplace
(en vez del comentado streaming en donde el repositorio ya esta consolidado).
(en vez del comentado streaming en donde el repositorio ya esta consolidado).
Por último recordar que muchos de los errores habituales en las
cargas estánrelacionados con el juego de datos de origen: por ejemplo,
con los encodings de los ficheros, con los permisos de acceso, con
documentos corruptos cuyo mimetype no coincide con su extensión, con
documentos de tamaño cero, o con documentos y carpetas ocultas en el
directorio origen. También apuntar que rsync es tu amigo a la hora de
sincronizar un determinado contenstore vivo con el directorio de
importacion en nuestro servidor.
cargas estánrelacionados con el juego de datos de origen: por ejemplo,
con los encodings de los ficheros, con los permisos de acceso, con
documentos corruptos cuyo mimetype no coincide con su extensión, con
documentos de tamaño cero, o con documentos y carpetas ocultas en el
directorio origen. También apuntar que rsync es tu amigo a la hora de
sincronizar un determinado contenstore vivo con el directorio de
importacion en nuestro servidor.





